
The worm situation seems to be getting worse, but fortunately worm makers fail to exploint the full potential of the vulnerabilities they use. For instance, we were all waiting to see what would happen to the Windows Update site when the "MS Blaster" worm was going to attack it on august 16th. But nothing happened. I read that Microsoft took the site offline to avoid problems, having no intention to bring it back online again, but obviously this information was incorrect because they're (back?) online now.
However, Microsoft received help from another worm creator who took it upon him/herself to fix the security hole that Blaster exploits, by first exploiting the same vulnerability, then removing Blaster and finally downloading Microsoft's patch. But in order to help scanning, the new worm (called "Nachi") first pings potential target, leading to huge ICMP floods in some networks, although others didn't see much traffic generated by the new worm. Nachi uses an uncommong ICMP echo request packet size of 92 bytes, which makes it possible to filter the worm without having to block all ping traffic. See Cisco's recommendations. It seems TNT dial-up concentrators have a hard time handling this traffic and reboot periodically. The issue seems to be lack of memory/CPU to cache all the destinations the worm tries to contact, just like what happened with the MS SQL worm earlier this year and others before it.
Then there's the Sobig worm. This one uses email to spread, which has two advantages: the users actually see the worm so they can't ignore the issue and the network impact is negligible as the spread speed is limited by mail server capacity. Unfortunately, this one forges the source with email addresses found on the infected computer, which means "innocent bystanders" receive the blame for sending out the worm. Interestingly enough, I haven't received a single copy of either this worm or its backscatter so far, even though it seems to be rather aggressive, many people report receiving lots (even thousands) of copies.
Then on friday there was a new development as it was discovered that Sobig would contact 20 IP addresses at 1900 UTC, presumably to receive new instructions/malicious code. 19 of the addresses were offline by this time, and the remaining one immediately became heavily congested. So far, nobody has been able to determine what was supposed to happen, but presumably, it didn't.
There was some discussion on the NANOG list about whether it's a good idea to block TCP/UDP ports to help stop or slow down worms. The majority of those who posted their opinion on the subject feel that the network shouldn't interfere with what users are doing, unless the network itself is at risk. This means temporary filters when there is a really aggressive worm on the loose, but not permanently filtering every possible vulnerable service. However, a sizable minority is in favor of this. But apart from philosophical preferences, it makes little sense to do this as the more you filter, the bigger the impact for legitimate users, and it has been well-established that worms manage to bypass filters and firewalls, presumably through VPNs or because people bring in infected laptops and connect them to the internal network.
Something to look forward to: with IPv6, there are so many addresses (even in a single subnet) that simply generating random addresses and see if there is a vulnerable host there isn't a usable approach. On the other hand, I've already seen scans on a virtual WWW server which means that the scanning happened using the DNS name rather than the server's IP address, so it's unlikely that the IPv6 internet will remain completely wormfree, even if things won't be as bad as they're now in IPv4.
Permalink - posted 2003-08-24
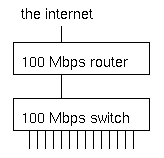
What's wrong with this picture?
Under normal circumstances, not much. But when several machines are infected with an aggressive worm or participating in a denial of service attack when an attacker has compromised them, the switch will receive more traffic from the hosts that are connected to the 100 Mbps ports than it can transmit to the router, which also has a 100 Mbps port.
The result is that a good part of alll traffic is dropped by the switch. This doesn't matter much to the abusive hosts, but the high packet loss makes it very hard or even impossible for the other hosts to communicate over the net. We've seen this happen with the MS SQL worm in january of this year, and very likely the same will happen on august 16th when machines infected with the "Blaster" worm (who comes up with these silly names anyway?) start a distributed denial of service attack on the Windows Update website. Hopefully the impact will be mitigated by the advance warning.
So what can we do? Obviously, within our own networks we should make sure hosts and servers aren't vulnerable, not running and/or exposing vulnerable services and quickly fixing any and all infections. However, for service or hosting providers it isn't as simple, as there will invariably be customers that don't follow best practices. Since it very close to impossible to have a network without any places where traffic is funneled/aggregated, it's essential to have routers or switches that can handle the full load of all the hosts on the internal network sending at full speed and then filter this traffic or apply quality of service measures such as rate limiting or priority queuing.
This is what multilayer switches and layer 3 switches such as the Cisco 6500 series switches with a router module or Foundry, Extreme and Riverstone router/switches can do very well, but these are obviously significantly more expensive than regular switches. It should still be possible to use "dumb" aggregation switches, but only if the uplink capacity is equal or higher than the combined inputs. So a 48 port 10/100 switch that connects to a filter-capable router/switch with gigabit ethernet, could support 5 ports at 100 Mbps and the remaining 43 ports at 10 Mbps. In practice a switch with 24 or 48 100 Mbps ports and a gigabit uplink or 24 or 48 10 Mbps ports with a fast ethernet uplink will probably work ok, as it is unlikely that more than 40% or even 20% of all hosts are going to be infected at the same time, but the not uncommon practice of aggregating 24 100 Mbps ports into a 100 Mbps uplink is way too dangerous these days.
Stay tuned for more worm news soon.
Permalink - posted 2003-08-14
At the Network and Distributed System Security Symposium 2003 (sponsored by the NSA), a group of researchers from AT&T Labs Research (and one from Harvard) presented a new approach to increasing interdomain routing security. Unlike Secure BGP (S-BGP) and Secure Origin BGP (soBGP), this approach carefully avoids making any changes to BGP. Instead, the necessary processing is done on an external box: the Interdomain Routing Validator that implements the Interdomain Routing Validation (IVR) protocol. The IRV stays in contact with all BGP routers within the AS and holds a copy of the AS's routing policy. The idea is that IRVs from different ASes contact each other on reception of BGP update messages to check whether the update is valid.
See the paper Working Around BGP: An Incremental Approach to Improving Security and Accuracy of Interdomain Routing in the NDSS'03 proceedings for the details. It's a bit wordy at 11 two column pages (in PDF), but it does a good job of explaining some of the BGP security problems and the S-BGP approach in addition to the IRV architecture.
This isn't a bad idea per se, however, the authors fail to address some important issues. For instance, they don't discuss the fact that routers only propagate the best route over BGP, making it impossible for the IVR to get a complete view of all incoming BGP updates. They don't discuss the security and reliability implications of having a centralized service for finding the IRVs associated with each AS. Last but not least, there is no discussion of what exactly happens when invalid BGP information is discovered.
The fact that that peering policies are deemed potentiallly "secret" more than once also strikes me as odd. How exactly are ISPs going to hide this information from their BGP-speaking customers? Or anyone who knows how to use the traceroute command, for that matter?
Still, I hope they'll bring this work into the IETF or at least one of the fora where interdomain routing operation is discussed, such as NANOG or RIPE.
Permalink - posted 2003-08-10
In an article for the Australian Commsworld site, Juniper's Jeff Doyle explains his views on the need for IPv6. He has little patience with the scare tactics some IPv6 proponents use, but rather argues that IPv6 is simply progress and it will be cheaper to administrate in the long run.
Permalink - posted 2003-08-03
The SANS (SysAdmin, Audit, Network, Security) Institute has published Is The Border Gateway Protocol Safe?. a paper (PDF) on different security aspects of BGP. Nothing groundbreaking, but detailed an a good read for people with a sysadmin background.
Permalink - posted 2003-08-03
Yet another worm analysis article: Effects of Worms on Internet Routing Stability on the SecurityFocus site. This one covers Code Red, Nimda and the SQL worm. No prizes for guessing which had the most impact on the stability of the global routing infrastructure.
Yes, it's old news, unlike Cisco's latest vulnerability (which just seems like very old news) but this stuff isn't going away and we have to deal with it. Are your routers prepared for another one of these worms?
Permalink - posted 2003-08-03